Rexpondo, Service Desk Software Solution
Ticketing and ITSM software based on
((OTRS)) Community Edition.
Available in Cloud and On premise.
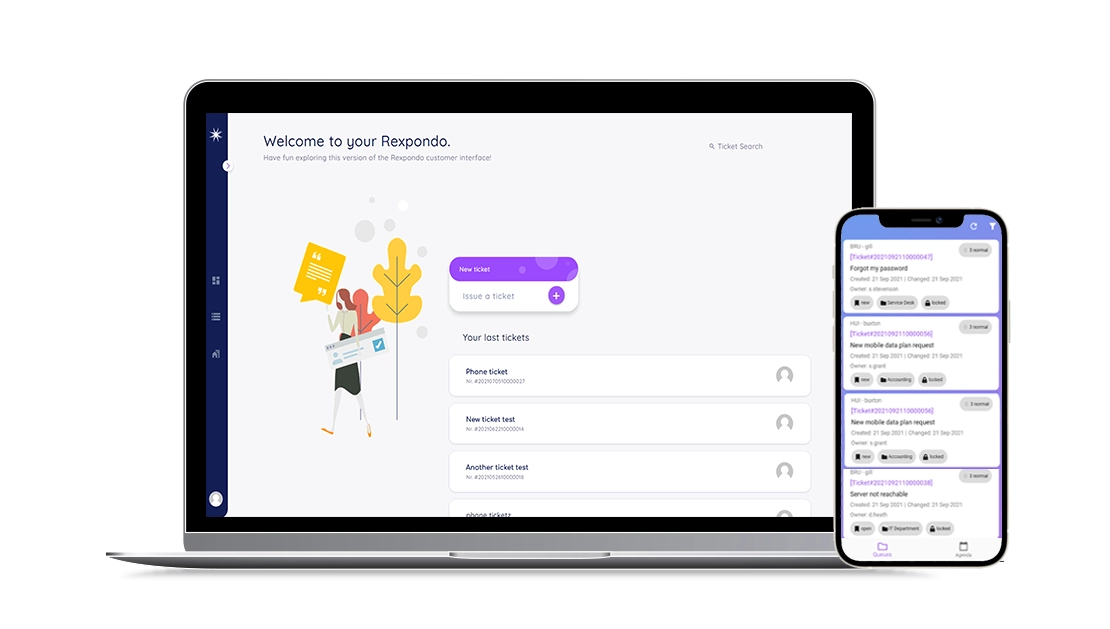
A Service Desk system taylored on your needs
A Service Desk system that guarantees maximum flexibility for your business needs from customer service to the management of the corporate IT infrastructure.
Ticketing
Use the ticketing system for your company’s internal needs and issues and for your customer services. Monitor response times and assign tickets to available operators.
ITSM
By adding the ITSM module, Rexpondo becomes an ITSM system embracing all best ITIL practices. It provides CMDB, Process and Change management and other functionalities.
IT & CX
Optimize IT support and make your Customers happy. Keep track of all tickets, reduce request answering times and keep control of your assets with focus on performance and security.
Learn More

.rexpondo/service-desk-solution
A software based on ((OTRS)) Community edition
Rexpondo still guarantee security updates, support and new features for all those companies that up to now have invested in OTRS.
- No licence fees
- Cloud or On-premise
- Fully customisable
Essential for managing communication and IT support
Over the years we have matured extensive experience in many sectors and we cannot wait to take on new ones.






Some of our clients















